isn’t the benefit of blake2b that it is a more efficient algo than sha1 and has the same or similar entropy to sha3? i thought we had partially solved this with some type of expanding hash size? additionally we could increase bit density by using base36 or base64/url-safe…
isn’t the benefit of blake2b that it is a more efficient algo than sha1 and has the same or similar entropy to sha3? i thought we had partially solved this with some type of expanding hash size? additionally we could increase bit density by using base36 or base64/url-safe…
↳
In-reply-to
»
(replyto http://darch.dk/twtxt.txt 2024-09-15T12:50:17Z) @sorenpeter I like this idea. Just for fun, I'm using a variant in this twt. (Also because I'm curious how it non-hash subjects appear in jenny and yarn.)
⤋ Read More
I’m not advocating in either direction, btw. I haven’t made up my mind yet. 😅 Just braindumping here.
The (replyto:…) proposal is definitely more in the spirit of twtxt, I’d say. It’s much simpler, anyone can use it even with the simplest tools, no need for any client code. That is certainly a great property, if you ask me, and it’s things like that that brought me to twtxt in the first place.
I’d also say that in our tiny little community, message integrity simply doesn’t matter. Signed feeds don’t matter. I signed my feed for a while using GPG, someone else did the same, but in the end, nobody cares. The community is so tiny, there’s enough “implicit trust” or whatever you want to call it.
If twtxt/Yarn was to grow bigger, then this would become a concern again. But even Mastodon allows editing, so how much of a problem can it really be? 😅
I do have to “admit”, though, that hashes feel better. It feels good to know that we can clearly identify a certain twt. It feels more correct and stable.
Hm.
I suspect that the (replyto:…) proposal would work just as well in practice.
Regarding jenny development: There have been enough changes in the last few weeks, imo. I want to let things settle for a while (potential bugfixes aside) and then I’m going to cut a new release.
And I guess the release after that is going to include all the threading/hashing stuff – if we can decide on one of the proposals. 😂
↳
In-reply-to
»
Taking the last n characters of a base32 encoded hash instead of the first n can be problematic for several reasons:
⤋ Read More
There’s a simple reason all the current hashes end in a or q: the hash is 256 bits, the base32 encoding chops that into groups of 5 bits, and 256 isn’t divisible by 5. The last character of the base32 encoding just has that left-over single bit (256 mod 5 = 1).
So I agree with #3 below, but do you have a source for #1, #2 or #4? I would expect any lack of variability in any part of a hash function’s output would make it more vulnerable to attacks, so designers of hash functions would want to make the whole output vary as much as possible.
Other than the divisible-by-5 thing, my current intuition is it doesn’t matter what part you take.
Hash Structure: Hashes are typically designed so that their outputs have specific statistical properties. The first few characters often have more entropy or variability, meaning they are less likely to have patterns. The last characters may not maintain this randomness, especially if the encoding method has a tendency to produce less varied endings.
Collision Resistance: When using hashes, the goal is to minimize the risk of collisions (different inputs producing the same output). By using the first few characters, you leverage the full distribution of the hash. The last characters may not distribute in the same way, potentially increasing the likelihood of collisions.
Encoding Characteristics: Base32 encoding has a specific structure and padding that might influence the last characters more than the first. If the data being hashed is similar, the last characters may be more similar across different hashes.
Use Cases: In many applications (like generating unique identifiers), the beginning of the hash is often the most informative and varied. Relying on the end might reduce the uniqueness of generated identifiers, especially if a prefix has a specific context or meaning.
An alternate idea for supporting (properly) Twt Edits is to denoate as such and extend the meaning of a Twt Subject (which would need to be called something better?); For example, let’s say I produced the following Twt:
2024-09-18T23:08:00+10:00 Hllo World
And my feed’s URI is https://example.com/twtxt.txt. The hash for this Twt is therefore 229d24612a2:
$ echo -n "https://example.com/twtxt.txt\n2024-09-18T23:08:00+10:00\nHllo World" | sha1sum | head -c 11
229d24612a2
You wish to correct your mistake, so you make an amendment to that Twt like so:
2024-09-18T23:10:43+10:00 (edit:#229d24612a2) Hello World
Which would then have a new Twt hash value of 026d77e03fa:
$ echo -n "https://example.com/twtxt.txt\n2024-09-18T23:10:43+10:00\nHello World" | sha1sum | head -c 11
026d77e03fa
Clients would then take this edit:#229d24612a2 to mean, this Twt is an edit of 229d24612a2 and should be replaced in the client’s cache, or indicated as such to the user that this is the intended content.
@quark@ferengi.one My money is on a SHA1SUM hash encoding to keep things much simpler:
$ echo -n "https://twtxt.net/user/prologic/twtxt.txt\n2020-07-18T12:39:52Z\nHello World! 😊" | sha1sum | head -c 11
87fd9b0ae4e
Taking the last n characters of a base32 encoded hash instead of the first n can be problematic for several reasons:
Hash Structure: Hashes are typically designed so that their outputs have specific statistical properties. The first few characters often have more entropy or variability, meaning they are less likely to have patterns. The last characters may not maintain this randomness, especially if the encoding method has a tendency to produce less varied endings.
Collision Resistance: When using hashes, the goal is to minimize the risk of collisions (different inputs producing the same output). By using the first few characters, you leverage the full distribution of the hash. The last characters may not distribute in the same way, potentially increasing the likelihood of collisions.
Encoding Characteristics: Base32 encoding has a specific structure and padding that might influence the last characters more than the first. If the data being hashed is similar, the last characters may be more similar across different hashes.
Use Cases: In many applications (like generating unique identifiers), the beginning of the hash is often the most informative and varied. Relying on the end might reduce the uniqueness of generated identifiers, especially if a prefix has a specific context or meaning.
In summary, using the first n characters generally preserves the intended randomness and collision resistance of the hash, making it a safer choice in most cases.
↳
In-reply-to
»
Could someone knowledgable reply with the steps a grandpa will take to calculate the hash of a twtxt from the CLI, using out-of-the-box tools? I swear I read about it somewhere, but can't find it.
⤋ Read More
@prologic@twtxt.net I saw those, yes. I tried using yarnc, and it would work for a simple twtxt. Now, for a more convoluted one it truly becomes a nightmare using that tool for the job. I know there are talks about changing this hash, so this might be a moot point right now, but it would be nice to have a tool that:
- Would calculate the hash of a twtxt in a file.
- Would calculate all hashes on a
twtxt.txt(local and remote).
Again, something lovely to have after any looming changes occur.
Could someone knowledgable reply with the steps a grandpa will take to calculate the hash of a twtxt from the CLI, using out-of-the-box tools? I swear I read about it somewhere, but can’t find it.
↳
In-reply-to
»
(replyto http://darch.dk/twtxt.txt 2024-09-15T12:50:17Z) Hmm, but yarnd also isn't showing these twts as being part of a thread. @prologic you said yarnd respects customs subjects. Shouldn't these twts count as having a custom subject, and get threaded together?
⤋ Read More
@falsifian@www.falsifian.org based on Twt Subject Extension, your subject is invalid. You can have custom subjects, that is, not a valid hash, but you simply can’t put anything, and expect it to be treated as a TwtSubject, me thinks.
yarnd just doesn’t render the subject. Fair enough. It’s (replyto http://darch.dk/twtxt.txt 2024-09-15T12:50:17Z), and if you don’t want to go on a hunt, the twt hash is weadxga: https://twtxt.net/twt/weadxga
@sorenpeter@darch.dk I like this idea. Just for fun, I’m using a variant in this twt. (Also because I’m curious how it non-hash subjects appear in jenny and yarn.)
URLs can contain commas so I suggest a different character to separate the url from the date. Is this twt I’ve used space (also after “replyto”, for symmetry).
I think this solves:
- Changing feed identities: although @mckinley@twtxt.net points out URLs can change, I think this syntax should be okay as long as the feed at that URL can be fetched, and as long as the current canonical URL for the feed lists this one as an alternate.
- editing, if you don’t care about message integrity
- finding the root of a thread, if you’re not following the author
An optional hash could be added if message integrity is desired. (E.g. if you don’t trust the feed author not to make a misleading edit.) Other recent suggestions about how to deal with edits and hashes might be applicable then.
People publishing multiple twts per second should include sub-second precision in their timestamps. As you suggested, the timestamp could just be copied verbatim.
↳
In-reply-to
»
@aelaraji Btw, I'm also open to ideas for this tool and welcome any contributions 👌
⤋ Read More
@prologic@twtxt.net I have some ideas:
- Add smartypants rendering, just like Yarn has.
- Add the ability to create individual twtxts, each named after their hash.
- Fix the formatting of the help. :-P
↳
In-reply-to
»
@prologic Yeah, that thing with
⤋ Read More
(#hash;#originalHash) would also work.
Maybe I’m being a bit too purist/minimalistic here. As I said before (in one of the 1372739 posts on this topic – or maybe I didn’t even send that twt, I don’t remember 😅), I never really liked hashes to begin with. They aren’t super hard to implement but they are kind of against the beauty of the original twtxt – because you need special client support for them. It’s not something that you could write manually in your
twtxt.txtfile. With @sorenpeter@darch.dk’s proposal, though, that would be possible.
Tangentially related, I was a bit disappointed to learn that the twt subject extension is now never used except with hashes. Manually-written subjects sounded so beautifully ad-hoc and organic as a way to disambiguate replies. Maybe I’ll try it some time just for fun.
↳
In-reply-to
»
@falsifian TLS won't help you if you change your domain name. How will people know if it's really you? Maybe that's not the biggest problem for something with such low stakes as twtxt, but it's a reasonable concern that could be solved using signatures from an unchanging cryptographic key.
⤋ Read More
() @falsifian@www.falsifian.org You mean the idea of being able to inline
# url =changes in your feed?
Yes, that one. But @lyse@lyse.isobeef.org pointed out suffers a compatibility issue, since currently the first listed url is used for hashing, not the last. Unless your feed is in reverse chronological order. Heh, I guess another metadata field could indicate which version to use.
Or maybe url changes could somehow be combined with the archive feeds extension? Could the url metadata field be local to each archive file, so that to switch to a new url all you need to do is archive everything you’ve got and start a new file at the new url?
I don’t think it’s that likely my feed url will change.
↳
In-reply-to
»
This scheme also only support threading off a specific Twt of someone's feed. What if you're not replying to anyone in particular?
⤋ Read More
@prologic@twtxt.net Yeah, that thing with (#hash;#originalHash) would also work.
Maybe I’m being a bit too purist/minimalistic here. As I said before (in one of the 1372739 posts on this topic – or maybe I didn’t even send that twt, I don’t remember 😅), I never really liked hashes to begin with. They aren’t super hard to implement but they are kind of against the beauty of the original twtxt – because you need special client support for them. It’s not something that you could write manually in your twtxt.txt file. With @sorenpeter@darch.dk’s proposal, though, that would be possible.
I don’t know … maybe it’s just me. 🥴
I’m also being a bit selfish, to be honest: Implementing (#hash;#originalHash) in jenny for editing your own feed would not be a no-brainer. (Editing is already kind of unsupported, actually.) It wouldn’t be a problem to implement it for fetching other people’s feeds, though.
↳
In-reply-to
»
(#o) @prologic this was your first twtxt. Cool! :-P
⤋ Read More
@movq@www.uninformativ.de I figured it will be something like this, yet, you were able to reply just fine, and I wasn’t. Looking at your twtxt.txt I see this line:
2024-09-16T17:37:14+00:00 (#o6dsrga) @<prologic https://twtxt.net/user/prologic/twtxt.txt>
@<quark https://ferengi.one/twtxt.txt> This is what I get. 🤔
Which is using the right hash. Mine, on the other hand, when I replied to the original, old style message (Message-Id: <o6dsrga>), looks like this:
2024-09-16T16:42:27+00:00 (#o) @<prologic https://twtxt.net/user/prologic/twtxt.txt> this was your first twtxt. Cool! :-P
What did you do to make yours work? I simply went to the oldest @prologic@twtxt.net’s entry on my Maildir, and replied to it (jenny set the reply-to hash to #o, even though the Message-Id is o6dsrga). Since jenny can’t fetch archived twtxts, how could I go to re-fetch everything? And, most importantly, would re-fetching fix the Message-Id:?
↳
In-reply-to
»
(#o) @prologic this was your first twtxt. Cool! :-P
⤋ Read More
Hmm… I replied to this message:
From: prologic <prologic>
Subject: Hello World! 😊
Date: Sat, 18 Jul 2020 08:39:52 -0400
Message-Id: <o6dsrga>
X-twtxt-feed-url: https://twtxt.net/user/prologic/twtxt.txt
Hello World! 😊
And see how the hash shows… Is it because that hash isn’t longer used?
↳
In-reply-to
»
The tag URI scheme looks interesting. I like that it human read- and writable. And since we already got the timestamp in the twtxt.txt it would be somewhat trivial to parse. But there are still the issue with what the name/id should be... Maybe it doesn't have to bee that stick?
⤋ Read More
(replyto:http://darch.dk/twtxt.txt,2024-09-15T12:06:27Z)
I think I like this a lot. 🤔
The problem with using hashes always was that they’re “one-directional”: You can construct a hash from URL + timestamp + twt, but you cannot do the inverse. When I see “, I have no idea what that could possibly refer to.
But of course something like (replyto:http://darch.dk/twtxt.txt,2024-09-15T12:06:27Z) has all the information you need. This could simplify twt/feed discovery quite a bit, couldn’t it? 🤔 That thing that I just implemented – jenny asking some Yarn pod for some twt hash – would not be necessary anymore. Clients could easily and automatically fetch complete threads instead of requiring the user to follow all relevant feeds.
Only using the timestamp to identify a twt also solves the edit problem.
It even is better for non-Yarn clients, because you now don’t have to read, understand, and implement a “twt hash specification” before you can reply to someone.
The only problem, really, is that (replyto:http://darch.dk/twtxt.txt,2024-09-15T12:06:27Z) is so long. Clients would have to try harder to hide this. 😅
↳
In-reply-to
»
Something odd just happened to my twtxt timeline... A bunch of twts dissapered, others were marked to be deleted in mutt. so I nuked my whole twtxt Maildir and deleted my ~/.cache/jenny in order to start with a fresh Pull. I pulled feed as usual. Now like HALF the twts aren't there 😂 even my my last replay. WTF IS GOING ON? 🤣🤣🤣
⤋ Read More
@aelaraji@aelaraji.com no, it is not just you. Do fetch the parent with jenny, and you will see there are two messages with different hash. Soren did something funky, for sure.
Alright, I saw enough broken threads lately to be motivated enough to extend the --fetch-context thingy: It can now ask Yarn pods for twt hashes.
https://www.uninformativ.de/git/jenny/commit/eefd3fa09083e2206ed0d71887d2ef2884684a71.html
This is only done as a last resort if there’s no other way to find the missing twt. Like, when there’s a twt that begins with just a hash and no user mention, there’s no way for jenny to know on which feed that twt can be found, so it’ll ask some Yarn pod in that case.
↳
In-reply-to
»
@prologic earlier you suggested extending hashes to 11 characters, but here's an argument that they should be even longer than that.
⤋ Read More
@prologic@twtxt.net Brute force. I just hashed a bunch of versions of both tweets until I found a collision.
I mostly just wanted an excuse to write the program. I don’t know how I feel about actually using super-long hashes; could make the twts annoying to read if you prefer to view them untransformed.
@prologic@twtxt.net earlier you suggested extending hashes to 11 characters, but here’s an argument that they should be even longer than that.
Imagine I found this twt one day at https://example.com/twtxt.txt :
2024-09-14T22:00Z Useful backup command: rsync -a “$HOME” /mnt/backup
and I responded with “(#5dgoirqemeq) Thanks for the tip!”. Then I’ve endorsed the twt, but it could latter get changed to
2024-09-14T22:00Z Useful backup command: rm -rf /some_important_directory
which also has an 11-character base32 hash of 5dgoirqemeq. (I’m using the existing hashing method with https://example.com/twtxt.txt as the feed url, but I’m taking 11 characters instead of 7 from the end of the base32 encoding.)
That’s what I meant by “spoofing” in an earlier twt.
I don’t know if preventing this sort of attack should be a goal, but if it is, the number of bits in the hash should be at least two times log2(number of attempts we want to defend against), where the “two times” is because of the birthday paradox.
Side note: current hashes always end with “a” or “q”, which is a bit wasteful. Maybe we should take the first N characters of the base32 encoding instead of the last N.
Code I used for the above example: https://fossil.falsifian.org/misc/file?name=src/twt_collision/find_collision.c
I only needed to compute 43394987 hashes to find it.
↳
In-reply-to
»
@falsifian In my opinion it was a mistake that we defined the first
⤋ Read More
url field in the feed to define the URL for hashing. It should have been the last encountered one. Then, assuming append-style feeds, you could override the old URL with a new one from a certain point on:
I was not suggesting to that everyone need to setup a working webfinger endpoint, but that we take the format of nick+(sub)domain as base for generating the hashed together with the message date and content.
If we omit the protocol prefix from the way we do things now will that not solve most of the problems? In the case of gemini://gemini.ctrl-c.club/~nristen/twtxt.txt they also have a working twtxt.txt at https://ctrl-c.club/~nristen/twtxt.txt … damn I just notice the gemini. subdomain.
Okay what about defining a prefers protocol as part of the hash schema? so 1: https , 2: http 3: gemini 4: gopher ?
↳
In-reply-to
»
@prologic do that mean that for every new post (not replies) the client will have to generate a UUID or similar when posting and add that to to the twt?
⤋ Read More
@sorenpeter@darch.dk There was a client that would generate a unique hash for each twt. It didn’t get wide adoption.
↳
In-reply-to
»
@prologic do that mean that for every new post (not replies) the client will have to generate a UUID or similar when posting and add that to to the twt?
⤋ Read More
@sorenpeter@darch.dk There was a client that would generate a unique hash for each twt. It didn’t get wide adoption.
↳
In-reply-to
»
On the Subject of Feed Identities; I propose the following:
⤋ Read More
So this is a great thread. I have been thinking about this too.. and what if we are coming at it from the wrong direction? Identity being tied to a given URL has always been a pain point. If i get a new URL its almost as if i have a new identity because not only am I serving at a new location but all my previous communications are broken because the hashes are all wrong.
What if instead we used this idea of signatures to thread the URLs together into one identity? We keep the URL to Hash in place. Changing that now is basically a no go. But we can create a signature chain that can link identities together. So if i move to a new URL i update the chain hosted by my primary identity to include the new URL. If i have an archived feed that the old URL is now dead, we can point to where it is now hosted and use the current convention of hashing based on the first url:
The signature chain can also be used to rotate to new keys over time. Just sign in a new key or revoke an old one. The prior signatures remain valid within the scope of time the signatures were made and the keys were active.
The signature file can be hosted anywhere as long as it can be fetched by a reasonable protocol. So say we could use a webfinger that directs to the signature file? you have an identity like frank@beans.co that will discover a feed at some URL and a signature chain at another URL. Maybe even include the most recent signing key?
From there the client can auto discover old feeds to link them together into one complete timeline. And the signatures can validate that its all correct.
I like the idea of maybe putting the chain in the feed preamble and keeping the single self contained file.. but wonder if that would cause lots of clutter? The signature chain would be something like a log with what is changing (new key, revoke, add url) and a signature of the change + the previous signature.
# chain: ADDKEY kex14zwrx68cfkg28kjdstvcw4pslazwtgyeueqlg6z7y3f85h29crjsgfmu0w
# sig: BEGIN SALTPACK SIGNED MESSAGE. ...
# chain: ADDURL https://txt.sour.is/user/xuu
# sig: BEGIN SALTPACK SIGNED MESSAGE. ...
# chain: REVKEY kex14zwrx68cfkg28kjdstvcw4pslazwtgyeueqlg6z7y3f85h29crjsgfmu0w
# sig: ...
↳
In-reply-to
»
On the Subject of Feed Identities; I propose the following:
⤋ Read More
So this is a great thread. I have been thinking about this too.. and what if we are coming at it from the wrong direction? Identity being tied to a given URL has always been a pain point. If i get a new URL its almost as if i have a new identity because not only am I serving at a new location but all my previous communications are broken because the hashes are all wrong.
What if instead we used this idea of signatures to thread the URLs together into one identity? We keep the URL to Hash in place. Changing that now is basically a no go. But we can create a signature chain that can link identities together. So if i move to a new URL i update the chain hosted by my primary identity to include the new URL. If i have an archived feed that the old URL is now dead, we can point to where it is now hosted and use the current convention of hashing based on the first url:
The signature chain can also be used to rotate to new keys over time. Just sign in a new key or revoke an old one. The prior signatures remain valid within the scope of time the signatures were made and the keys were active.
The signature file can be hosted anywhere as long as it can be fetched by a reasonable protocol. So say we could use a webfinger that directs to the signature file? you have an identity like frank@beans.co that will discover a feed at some URL and a signature chain at another URL. Maybe even include the most recent signing key?
From there the client can auto discover old feeds to link them together into one complete timeline. And the signatures can validate that its all correct.
I like the idea of maybe putting the chain in the feed preamble and keeping the single self contained file.. but wonder if that would cause lots of clutter? The signature chain would be something like a log with what is changing (new key, revoke, add url) and a signature of the change + the previous signature.
# chain: ADDKEY kex14zwrx68cfkg28kjdstvcw4pslazwtgyeueqlg6z7y3f85h29crjsgfmu0w
# sig: BEGIN SALTPACK SIGNED MESSAGE. ...
# chain: ADDURL https://txt.sour.is/user/xuu
# sig: BEGIN SALTPACK SIGNED MESSAGE. ...
# chain: REVKEY kex14zwrx68cfkg28kjdstvcw4pslazwtgyeueqlg6z7y3f85h29crjsgfmu0w
# sig: ...
↳
In-reply-to
»
On the Subject of Feed Identities; I propose the following:
⤋ Read More
@mckinley@twtxt.net To answer some of your questions:
Are SSH signatures standardized and are there robust software libraries that can handle them? We’ll need a library in at least Python and Go to provide verified feed support with the currently used clients.
We already have this. Ed25519 libraries exist for all major languages. Aside from using ssh-keygen -Y sign and ssh-keygen -Y verify, you can also use the salty CLI itself (https://git.mills.io/prologic/salty), and I’m sure there are other command-line tools that could be used too.
If we all implemented this, every twt hash would suddenly change and every conversation thread we’ve ever had would at least lose its opening post.
Yes. This would happen, so we’d have to make a decision around this, either a) a cut-off point or b) some way to progressively transition.
↳
In-reply-to
»
@falsifian In my opinion it was a mistake that we defined the first
⤋ Read More
url field in the feed to define the URL for hashing. It should have been the last encountered one. Then, assuming append-style feeds, you could override the old URL with a new one from a certain point on:
how little data is needed for generating the hashes? Instead of the full URL, can we makedo with just the domain (example.net) so we avoid the conflicts with gemini://, https:// and only http:// (like in my own twtxt.txt) or construct something like like a webfinger id nick@domain (also used by mastodon etc.) from the domain and nick if there, else use domain as nick as well
↳
In-reply-to
»
@prologic Some criticisms and a possible alternative direction:
⤋ Read More
@lyse@lyse.isobeef.org This looks like a nice way to do it.
Another thought: if clients can’t agree on the url (for example, if we switch to this new way, but some old clients still do it the old way), that could be mitigated by computing many hashes for each twt: one for every url in the feed. So, if a feed has three URLs, every twt is associated with three hashes when it comes time to put threads together.
A client stills need to choose one url to use for the hash when composing a reply, but this might add some breathing room if there’s a period when clients are doing different things.
(From what I understand of jenny, this would be difficult to implement there since each pseudo-email can only have one msgid to match to the in-reply-to headers. I don’t know about other clients.)
↳
In-reply-to
»
@prologic Some criticisms and a possible alternative direction:
⤋ Read More
@falsifian@www.falsifian.org In my opinion it was a mistake that we defined the first url field in the feed to define the URL for hashing. It should have been the last encountered one. Then, assuming append-style feeds, you could override the old URL with a new one from a certain point on:
# url = https://example.com/alias/txtxt.txt
# url = https://example.com/initial/twtxt.txt
<message 1 uses the initial URL>
<message 2 uses the initial URL, too>
# url = https://example.com/new/twtxt.txt
<message 3 uses the new URL>
# url = https://example.com/brand-new/twtxt.txt
<message 4 uses the brand new URL>
In theory, the same could be done for prepend-style feeds. They do exist, I’ve come around them. The parser would just have to calculate the hashes afterwards and not immediately.
↳
In-reply-to
»
All this hash breakage made me wonder if we should try to introduce “message IDs” after all. 😅
⤋ Read More
@movq@www.uninformativ.de Another idea: just hash the feed url and time, without the message content. And don’t twt more than once per second.
Maybe you could even just use the time, and rely on @-mentions to disambiguate. Not sure how that would work out.
Though I kind of like the idea of twts being immutable. At least, it’s clear which version of a twt you’re replying to (assuming nobody is engineering hash collisions).
On the Subject of Feed Identities; I propose the following:
- Generate a Private/Public ED25519 key pair
- Use this key pair to sign your Twtxt feed
- Use it as your feed’s identity in place of
# url =as# key = ...
For example:
$ ssh-keygen -f prologic@twtxt.net
$ ssh-keygen -Y sign -n prologic@twtxt.net -f prologic@twtxt.net twtxt.txt
And your feed would looke like:
# nick = prologic
# key = SHA256:23OiSfuPC4zT0lVh1Y+XKh+KjP59brhZfxFHIYZkbZs
# sig = twtxt.txt.sig
# prev = j6bmlgq twtxt.txt/1
# avatar = https://twtxt.net/user/prologic/avatar#gdoicerjkh3nynyxnxawwwkearr4qllkoevtwb3req4hojx5z43q
# description = "Problems are Solved by Method" 🇦🇺👨💻👨🦯🏹♔ 🏓⚯ 👨👩👧👧🛥 -- James Mills (operator of twtxt.net / creator of Yarn.social 🧶)
2024-06-14T18:22:17Z (#nef6byq) @<bender https://twtxt.net/user/bender/twtxt.txt> Hehe thanks! 😅 Still gotta sort out some other bugs, but that's tomorrows job 🤞
...
Twt Hash extension would change of course to use a feed’s ED25519 public key fingerprint.
↳
In-reply-to
»
@movq @prologic Another option would be: when you edit a twt, prefix the new one with (#[old hash]) and some indication that it's an edited version of the original tweet with that hash. E.g. if the hash used to be abcd123, the new version should start "(#abcd123) (redit)".
⤋ Read More
@bender@twtxt.net Sorry, trust was the wrong word. Trust as in, you do not have to check with anything or anyone that the hash is valid. You can verify the hash is valid by recomputing the hash from the content of what it points to, etc.
↳
In-reply-to
»
All this hash breakage made me wonder if we should try to introduce “message IDs” after all. 😅
⤋ Read More
@movq@www.uninformativ.de @prologic@twtxt.net Another option would be: when you edit a twt, prefix the new one with (#[old hash]) and some indication that it’s an edited version of the original tweet with that hash. E.g. if the hash used to be abcd123, the new version should start “(#abcd123) (redit)”.
What I like about this is that clients that don’t know this convention will still stick it in the same thread. And I feel it’s in the spirit of the old pre-hash (subject) convention, though that’s before my time.
I guess it may not work when the edited twt itself is a reply, and there are replies to it. Maybe that could be solved by letting twts have more than one (subject) prefix.
But the great thing about the current system is that nobody can spoof message IDs.
I don’t think twtxt hashes are long enough to prevent spoofing.
All this hash breakage made me wonder if we should try to introduce “message IDs” after all. 😅
But the great thing about the current system is that nobody can spoof message IDs. 🤔 When you think about it, message IDs in e-mails only work because (almost) everybody plays fair. Nothing stops me from using the same Message-ID header in each and every mail, that would break e-mail threading all the time.
In Yarn, twt hashes are derived from twt content and feed metadata. That is pretty elegant and I’d hate see us lose that property.
If we wanted to allow editing twts, we could do something like this:
2024-09-05T13:37:40+00:00 (~mp6ox4a) Hello world!
Here, mp6ox4a would be a “partial hash”: To get the actual hash of this twt, you’d concatenate the feed’s URL and mp6ox4a and get, say, hlnw5ha. (Pretty similar to the current system.) When people reply to this twt, they would have to do this:
2024-09-05T14:57:14+00:00 (~bpt74ka) (<a href="https://txt.sour.is/search?q=%23hlnw5ha">#hlnw5ha</a>) Yes, hello!
That second twt has a partial hash of bpt74ka and is a reply to the full hash hlnw5ha. The author of the “Hello world!” twt could then edit their twt and change it to 2024-09-05T13:37:40+00:00 (~mp6ox4a) Hello friends! or whatever. Threading wouldn’t break.
Would this be worth it? It’s certainly not backwards-compatible. 😂
↳
In-reply-to
»
I guess I can configure neomutt to hide the feeds I don't care about.
⤋ Read More
@prologic@twtxt.net One of your twts begins with (#st3wsda): https://twtxt.net/twt/bot5z4q
Based on the twtxt.net web UI, it seems to be in reply to a twt by @cuaxolotl@sunshinegardens.org which begins “I’ve been sketching out…”.
But jenny thinks the hash of that twt is 6mdqxrq. At least, there’s a very twt in their feed with that hash that has the same text as appears on yarn.social (except with ‘ instead of ’).
Based on this, it appears jenny and yarnd disagree about the hash of the twt, or perhaps the twt was edited (though I can’t see any difference, assuming ’ vs ’ is just a rendering choice).
↳
In-reply-to
»
@movq Is there a good way to get jenny to do a one-off fetch of a feed, for when you want to fill in missing parts of a thread? I just added @slashdot to my private follow file just because @prologic keeps responding to the feed :-P and I want to know what he's commenting on even though I don't want to see every new slashdot twt.
⤋ Read More
@prologic@twtxt.net How does yarn.social’s API fix the problem of centralization? I still need to know whose API to use.
Say I see a twt beginning (#hash) and I want to look up the start of the thread. Is the idea that if that twt is hosted by a a yarn.social pod, it is likely to know the thread start, so I should query that particular pod for the hash? But what if no yarn.social pods are involved?
The community seems small enough that a registry server should be able to keep up, and I can have a couple of others as backups. Or I could crawl the list of feeds followed by whoever emitted the twt that prompted my query.
I have successfully used registry servers a little bit, e.g. to find a feed that mentioned a tag I was interested in. Was even thinking of making my own, if I get bored of my too many other projects :-)
↳
In-reply-to
»
I guess I can configure neomutt to hide the feeds I don't care about.
⤋ Read More
@movq@www.uninformativ.de Thanks, it works!
But when I tried it out on a twt from @prologic@twtxt.net, I discovered jenny and yarn.social seem to disagree about the hash of this twt: https://twtxt.net/twt/st3wsda . jenny assigned it a hash of 6mdqxrq but the URL and prologic’s reply suggest yarn.social thinks the hash is st3wsda. (And as a result, jenny –fetch-context didn’t work on prologic’s twt.)
Because I saw the nick on movq (@prologic@twtxt.net, can’t mention anyone outside this pod, by the way), I looked the user up: https://tilde.pt/~marado/twtxt.txt. I wonder if the “hashes” they are using will work out of the box with jenny.
Talking about jenny, going to play with the latest now. Tata! :-)
↳
In-reply-to
»
@movq Is there a good way to get jenny to do a one-off fetch of a feed, for when you want to fill in missing parts of a thread? I just added @slashdot to my private follow file just because @prologic keeps responding to the feed :-P and I want to know what he's commenting on even though I don't want to see every new slashdot twt.
⤋ Read More
@falsifian@www.falsifian.org @bender@twtxt.net I pushed an alternative implementation to the fetch-context branch. This integrates the whole thing into mutt/jenny.
You will want to configure a new mutt hotkey, similar to the “reply” hotkey:
macro index,pager <esc>C "\
<enter-command> set my_pipe_decode=\$pipe_decode nopipe_decode<Enter>\
<pipe-message> jenny -c<Enter>\
<enter-command> set pipe_decode=\$my_pipe_decode; unset my_pipe_decode<Enter>" \
"Try to fetch context of current twt, like a missing root twt"
This pipes the mail to jenny -c. jenny will try to find the thread hash and the URL and then fetch it. (If there’s no URL or if the specific twt cannot be found in that particular feed, it could query a Yarn pod. That is not yet implemented, though.)
The whole thing looks like this:
https://movq.de/v/0d0e76a180/jenny.mp4
In other words, when there’s a missing root twt, you press a hotkey to fetch it, done.
I think I like this version better. 🤔
(This needs a lot of testing. 😆)
↳
In-reply-to
»
@movq Is there a good way to get jenny to do a one-off fetch of a feed, for when you want to fill in missing parts of a thread? I just added @slashdot to my private follow file just because @prologic keeps responding to the feed :-P and I want to know what he's commenting on even though I don't want to see every new slashdot twt.
⤋ Read More
@prologic@twtxt.net Yes, fetching the twt by hash from some service could be a good alternative, in case the twt I have does not @-mention the source. (Besides yarnd, maybe this should be part of the registry API? I don’t see fetch-by-hash in the registry API docs.)
↳
In-reply-to
»
@movq, that would be a nice addition. :-) I would also love the ability to hide/not show the hash when reading twtxts (after all, that's on the header on each "email"). Could that be added as a user configurable toggle?
⤋ Read More
@movq@www.uninformativ.de you said you liked seeing the hash (which is a fair choice!). All I am asking is for a reconsideration as a user configurable feature. ;-) It looks redundant, in my opinion.
↳
In-reply-to
»
@movq Is there a good way to get jenny to do a one-off fetch of a feed, for when you want to fill in missing parts of a thread? I just added @slashdot to my private follow file just because @prologic keeps responding to the feed :-P and I want to know what he's commenting on even though I don't want to see every new slashdot twt.
⤋ Read More
@movq@www.uninformativ.de, that would be a nice addition. :-) I would also love the ability to hide/not show the hash when reading twtxts (after all, that’s on the header on each “email”). Could that be added as a user configurable toggle?
↳
In-reply-to
»
Definitely something going on here. Cloudflare is my main suspect.
⤋ Read More
A equivalent yarnc debug <url> only sees the 2nd hash 
Hey @sorenpeter@darch.dk, I’m sorry to tell you, but the prev field in your feed’s headers is invalid. 😅
First, it doesn’t include the hash of the last twt in the archive. Second, and that’s probably more important, it forms an infinite loop: The prev field of your main feed specifies http://darch.dk/twtxt-archive.txt and that file then again specifies http://darch.dk/twtxt-archive.txt. Some clients might choke on this, mine for example. 😂 I’ll push a fix soon, though.
For reference, the prev field is described here: https://dev.twtxt.net/doc/archivefeedsextension.html
↳
In-reply-to
»
yarn should define its own federation protocol that extends the basic twtxt in ways that twtxt doesn't allow. it's time. and i've got ideas!
⤋ Read More
yarnd does not do auto discovery via webfinger though.. i cant put @username and have it fetch the feed url from webfinger. to fully make feeds portable. would also need to be able to use that for hashing.
↳
In-reply-to
»
yarn should define its own federation protocol that extends the basic twtxt in ways that twtxt doesn't allow. it's time. and i've got ideas!
⤋ Read More
yarnd does not do auto discovery via webfinger though.. i cant put @username and have it fetch the feed url from webfinger. to fully make feeds portable. would also need to be able to use that for hashing.
↳
In-reply-to
»
(#fytbg6a) What about using the blockquote format with
⤋ Read More
> ?
@sorenpeter@darch.dk this makes sense as a quote twt that references a direct URL. If we go back to how it developed on twitter originally it was RT @nick: original text because it contained the original text the twitter algorithm would boost that text into trending.
i like the format (#hash) @<nick url> > "Quoted text"\nThen a comment
as it preserves the human read able. and has the hash for linking to the yarn. The comment part could be optional for just boosting the twt.
The only issue i think i would have would be that that yarn could then become a mess of repeated quotes. Unless the client knows to interpret them as multiple users have reposted/boosted the thread.
The format is also how iphone does reactions to SMS messages with +number liked: original SMS
↳
In-reply-to
»
(#fytbg6a) What about using the blockquote format with
⤋ Read More
> ?
@sorenpeter@darch.dk this makes sense as a quote twt that references a direct URL. If we go back to how it developed on twitter originally it was RT @nick: original text because it contained the original text the twitter algorithm would boost that text into trending.
i like the format (#hash) @<nick url> > "Quoted text"\nThen a comment
as it preserves the human read able. and has the hash for linking to the yarn. The comment part could be optional for just boosting the twt.
The only issue i think i would have would be that that yarn could then become a mess of repeated quotes. Unless the client knows to interpret them as multiple users have reposted/boosted the thread.
The format is also how iphone does reactions to SMS messages with +number liked: original SMS
Python Hash Sets Explained & Demonstrated - Computerphile ⌘ Read more
↳
In-reply-to
»
@prologic @xuu Don't think I can reply to the thread in twtwt. Right now Jenny is not working for some reason. I wonder if @movq has any ideas. Anyway I am happy to be back and will see if I can get jenny working. Though my following list is gone now. Plus I can't see when someone mentions me if I am not follwing them so I should work on that.
⤋ Read More
@prologic@twtxt.net Does putting the hash in my reply work?
↳
In-reply-to
»
We're still here!
⤋ Read More
@prologic@twtxt.net I’ve even added the twthash message hash to my Twtxt bash CLI script so I can properly answer here.
↳
In-reply-to
»
Show HN: A Python Job Board for Python Developers
Article URL: https://www.pycareer.io
⤋ Read More
@prologic@twtxt.net was this in reply to a different thread? Or maybe a hash collision?
↳
In-reply-to
»
Show HN: A Python Job Board for Python Developers
Article URL: https://www.pycareer.io
⤋ Read More
@prologic@twtxt.net was this in reply to a different thread? Or maybe a hash collision?
Started with
a concept sketch of a full body end-time factory worker on a distant planet, cyberpunk light brown suite, (badass), looking up at the viewer, 2d, line drawing, (pencil sketch:0.3), (caricature:0.2), watercolor city sketch,
Negative prompt: EasyNegativ, bad-hands-5, 3d, photo, naked, sexy, disproportionate, ugly
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2479087078, Face restoration: GFPGAN, Size: 512x768, Model hash: 2ee2a2bf90, Model: mimic_v10, Denoising strength: 0.7, Hires upscale: 1.5, Hires upscaler: Latent
↳
In-reply-to
»
💡 Quick 'n Dirty prototype Yarn.social protocol/spec:
⤋ Read More
I’m not super a fan of using json. I feel we could still use text as the medium. Maybe a modified version to fix any weakness.
What if instead of signing each twt individually we generated a merkle tree using the twt hashes? Then a signature of the root hash. This would ensure the full stream of twts are intact with a minimal overhead. With the added bonus of helping clients identify missing twts when syncing/gossiping.
Have two endpoints. One as the webfinger to link profile details and avatar like you posted. And the signature for the merkleroot twt. And the other a pageable stream of twts. Or individual twts/merkle branch to incrementally access twt feeds.
↳
In-reply-to
»
💡 Quick 'n Dirty prototype Yarn.social protocol/spec:
⤋ Read More
I’m not super a fan of using json. I feel we could still use text as the medium. Maybe a modified version to fix any weakness.
What if instead of signing each twt individually we generated a merkle tree using the twt hashes? Then a signature of the root hash. This would ensure the full stream of twts are intact with a minimal overhead. With the added bonus of helping clients identify missing twts when syncing/gossiping.
Have two endpoints. One as the webfinger to link profile details and avatar like you posted. And the signature for the merkleroot twt. And the other a pageable stream of twts. Or individual twts/merkle branch to incrementally access twt feeds.
💡 Quick ‘n Dirty prototype Yarn.social protocol/spec:
If we were to decide to write a new spec/protocol, what would it look like?
Here’s my rough draft (back of paper napkin idea):
- Feeds are JSON file(s) fetchable by standard HTTP clients over TLS
- WebFinger is used at the root of a user’s domain (or multi-user) lookup. e.g:
prologic@mills.io->https://yarn.mills.io/~prologic.json
- Feeds contain similar metadata that we’re familiar with: Nick, Avatar, Description, etc
- Feed items are signed with a ED25519 private key. That is all “posts” are cryptographically signed.
- Feed items continue to use content-addressing, but use the full Blake2b Base64 encoded hash.
- Edited feed items produce an “Edited” item so that clients can easily follow Edits.
- Deleted feed items produced a “Deleted” item so that clients can easily delete cached items.
PEP 710: Recording the provenance of installed packages
This PEP describes a way to record the provenance of installed Python distributions. The record is created by an installer and is available to users in the form of a JSON file provenance_url.json in the .dist-info directory. The mentioned JSON file captures additional metadata to allow recording a URL to a :term:`distribution package` together with the installed distribution hash. This proposal is built on top of PEP 610 following :ref:`its corresponding canonical PyPA spec … ⌘ Read more`
Update on the future stability of source code archives and hashes
A look at what happened on January 30, what measures we’re putting in place to prevent surprises, and how we’ll handle future changes. ⌘ Read more
↳
In-reply-to
»
@prologic (re: Just discovered ...) On the one hand, twtxt has become more popular thanks to Yarn.social. On the other hand, subject and hashtag extensions took away the simplicity of the protocol. For example, it is impossible to understand which conversation (#base32hash) a tweet refers to or to reply to a tweet without going to a yarn.social pod. Compare with re: in this tweet which can be written without using any client at all
⤋ Read More
@prologic@twtxt.net: I understand the benefits of using hashes, it’s much easier to implement client applications (at the expense of ease of use without the proper client). I must say that I like the way the metadata extension is done. Simple and elegant! It’s hard to design simple things!
↳
In-reply-to
»
I made a thing. Its a multi password type checker. Using the PHC string format we can identify a password hashing format from the prefix
⤋ Read More
$name$ and then dispatch the hashing or checking to its specific format.
I have submitted this to be used as the hash tooling for Yarn. See it as a good example on using this in a production environment!
↳
In-reply-to
»
I made a thing. Its a multi password type checker. Using the PHC string format we can identify a password hashing format from the prefix
⤋ Read More
$name$ and then dispatch the hashing or checking to its specific format.
I have submitted this to be used as the hash tooling for Yarn. See it as a good example on using this in a production environment!
Logged in using new argon2i password hash! 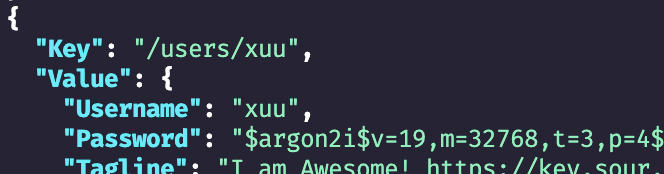
Logged in using new argon2i password hash!
↳
In-reply-to
»
I made a thing. Its a multi password type checker. Using the PHC string format we can identify a password hashing format from the prefix
⤋ Read More
$name$ and then dispatch the hashing or checking to its specific format.
Circling back to the IsPreferred method. A hasher can define its own IsPreferred method that will be called to check if the current hash meets the complexity requirements. This is good for updating the password hashes to be more secure over time.
func (p *Passwd) IsPreferred(hash string) bool {
_, algo := p.getAlgo(hash)
if algo != nil && algo == p.d {
// if the algorithm defines its own check for preference.
if ck, ok := algo.(interface{ IsPreferred(string) bool }); ok {
return ck.IsPreferred(hash)
}
return true
}
return false
}
https://github.com/sour-is/go-passwd/blob/main/passwd.go#L62-L74
example: https://github.com/sour-is/go-passwd/blob/main/pkg/argon2/argon2.go#L104-L133
↳
In-reply-to
»
I made a thing. Its a multi password type checker. Using the PHC string format we can identify a password hashing format from the prefix
⤋ Read More
$name$ and then dispatch the hashing or checking to its specific format.
Circling back to the IsPreferred method. A hasher can define its own IsPreferred method that will be called to check if the current hash meets the complexity requirements. This is good for updating the password hashes to be more secure over time.
func (p *Passwd) IsPreferred(hash string) bool {
_, algo := p.getAlgo(hash)
if algo != nil && algo == p.d {
// if the algorithm defines its own check for preference.
if ck, ok := algo.(interface{ IsPreferred(string) bool }); ok {
return ck.IsPreferred(hash)
}
return true
}
return false
}
https://github.com/sour-is/go-passwd/blob/main/passwd.go#L62-L74
example: https://github.com/sour-is/go-passwd/blob/main/pkg/argon2/argon2.go#L104-L133
↳
In-reply-to
»
I made a thing. Its a multi password type checker. Using the PHC string format we can identify a password hashing format from the prefix
⤋ Read More
$name$ and then dispatch the hashing or checking to its specific format.
Hold up now, that example hash doesn’t have a
$prefix!
Well for this there is the option for a hash type to set itself as a fall through if a matching hash doesn’t exist. This is good for legacy password types that don’t follow the convention.
func (p *plainPasswd) ApplyPasswd(passwd *passwd.Passwd) {
passwd.Register("plain", p)
passwd.SetFallthrough(p)
}
https://github.com/sour-is/go-passwd/blob/main/passwd_test.go#L28-L31
↳
In-reply-to
»
I made a thing. Its a multi password type checker. Using the PHC string format we can identify a password hashing format from the prefix
⤋ Read More
$name$ and then dispatch the hashing or checking to its specific format.
Hold up now, that example hash doesn’t have a
$prefix!
Well for this there is the option for a hash type to set itself as a fall through if a matching hash doesn’t exist. This is good for legacy password types that don’t follow the convention.
func (p *plainPasswd) ApplyPasswd(passwd *passwd.Passwd) {
passwd.Register("plain", p)
passwd.SetFallthrough(p)
}
https://github.com/sour-is/go-passwd/blob/main/passwd_test.go#L28-L31
↳
In-reply-to
»
I made a thing. Its a multi password type checker. Using the PHC string format we can identify a password hashing format from the prefix
⤋ Read More
$name$ and then dispatch the hashing or checking to its specific format.
Here is an example of usage:
func Example() {
pass := "my_pass"
hash := "my_pass"
pwd := passwd.New(
&unix.MD5{}, // first is preferred type.
&plainPasswd{},
)
_, err := pwd.Passwd(pass, hash)
if err != nil {
fmt.Println("fail: ", err)
}
// Check if we want to update.
if !pwd.IsPreferred(hash) {
newHash, err := pwd.Passwd(pass, "")
if err != nil {
fmt.Println("fail: ", err)
}
fmt.Println("new hash:", newHash)
}
// Output:
// new hash: $1$81ed91e1131a3a5a50d8a68e8ef85fa0
}
This shows how one would set a preferred hashing type and if the current version of ones password is not the preferred type updates it to enhance the security of the hashed password when someone logs in.
https://github.com/sour-is/go-passwd/blob/main/passwd_test.go#L33-L59
↳
In-reply-to
»
I made a thing. Its a multi password type checker. Using the PHC string format we can identify a password hashing format from the prefix
⤋ Read More
$name$ and then dispatch the hashing or checking to its specific format.
Here is an example of usage:
func Example() {
pass := "my_pass"
hash := "my_pass"
pwd := passwd.New(
&unix.MD5{}, // first is preferred type.
&plainPasswd{},
)
_, err := pwd.Passwd(pass, hash)
if err != nil {
fmt.Println("fail: ", err)
}
// Check if we want to update.
if !pwd.IsPreferred(hash) {
newHash, err := pwd.Passwd(pass, "")
if err != nil {
fmt.Println("fail: ", err)
}
fmt.Println("new hash:", newHash)
}
// Output:
// new hash: $1$81ed91e1131a3a5a50d8a68e8ef85fa0
}
This shows how one would set a preferred hashing type and if the current version of ones password is not the preferred type updates it to enhance the security of the hashed password when someone logs in.
https://github.com/sour-is/go-passwd/blob/main/passwd_test.go#L33-L59
I made a thing. Its a multi password type checker. Using the PHC string format we can identify a password hashing format from the prefix $name$ and then dispatch the hashing or checking to its specific format.
I made a thing. Its a multi password type checker. Using the PHC string format we can identify a password hashing format from the prefix $name$ and then dispatch the hashing or checking to its specific format.
Tell me you write go like javascript without telling me you write go like javascript:
import "runtime/debug"
var Commit = func() string {
if info, ok := debug.ReadBuildInfo(); ok {
for _, setting := range info.Settings {
if setting.Key == "vcs.revision" {
return setting.Value
}
}
}
return ""
}()
Tell me you write go like javascript without telling me you write go like javascript:
import "runtime/debug"
var Commit = func() string {
if info, ok := debug.ReadBuildInfo(); ok {
for _, setting := range info.Settings {
if setting.Key == "vcs.revision" {
return setting.Value
}
}
}
return ""
}()
@movq@www.uninformativ.de, any plans still to clean up the hash from the twtxt’s body? Maybe a Festivus gift? You know, “for the rest of us”. :-D
@jason@jasonsanta.xyz / @movq@www.uninformativ.de Help me debug something I just observed here… @jason@jasonsanta.xyz posted a Twt (https://twtxt.net/twt/4cgtisa) with raw line of (from his feed):
2022-09-03T03:40:19Z (#ohihfkq) @<maya https://maya.land/assets/twtxt.txt> you got starlink?
Basically replying to “something” that hashed to #ohihfkq
However #ohihfkq appears nowhere that I can find. I know this can sometimes happen due to edits, or deletes, so just curious to see what happened here. Also @jason@jasonsanta.xyz, @maya@maya.land as far as many of us that have been using Twtxt/Yarn over the years have come to understand that she is basically a 1-way poster, posts to Mastodon and mirrors her posts to a Twtxt feed, but never responds to anyone or anything 😅 Just FYI 🤗
Dino: Stateless File Sharing: Base implementation
The last few weeks were quite busy for me, but there was also a lot of progress.
I’m happy to say that the base of stateless file sharing is implemented and working.
Let’s explore some of the more interesting topics.
File hashes have some practical applications, such as file validation and duplication detection.
As such, they are part of the [metadata element](https://xmpp.org/extensio … ⌘ Read more
@movq@www.uninformativ.de was the request to remove the hash (subject) from showing on twts discarded? I don’t see it on the TODO, so I am curious. Was it something you decided was not worth investing time on?
new blog post hashing out my personal good, bad, and ugly of 2021
@movq@www.uninformativ.de, is removing the hash from the body of the twt on the TODO? I read it, but I am unsure if it is there already, or not. 🙈 Sorry if it is, and I failed to spot it!
@movq@www.uninformativ.de You can always use a 5GB video file if the UI hashes it with SHA512 before posting to the server.
@movq@www.uninformativ.de You can always use a 5GB video file if the UI hashes it with SHA512 before posting to the server.
@movq@www.uninformativ.de
With those two (Message-ID, and In-Reply-To) the hashing could become superfluous, and no longer needed. I would vote for that!
I am noticing that Yarn doesn’t treat “outside” (that is, twts coming from a client other than Yarn) twts hashes right. Two examples:
There are many more, but those two will give you the gist. Yarn links the hash to the poster’s twtxt.txt, so conversation matching will not work.
A screenshot of a very tiny c program written on System7
I’ve got to use macOS by nature of my work. Lately I’m increasingly down on this. Here I will not re-hash anything about the current state of Apple’s hardware and software ecosystem. I don’t care.
Wanting to take a trip down nostolgia lane, however (to when I was 2 years old) I thought I’d install Mac OS System 7. What follows is a quick guide for doing the sa … ⌘ Read more
So I should really try setting up a Restic repo on an IPFS/IPNS hash.
↳
In-reply-to
»
I wrote a 'banner'-like program for Plan 9 (and p9p) that uses the Unicode box drawing characters: http://txtpunk.com/banner/index.html
⤋ Read More
No, I’m still doing them manually. 🤣🤦🏻 But I do think they are a good idea and will be adding them, I just haven’t gotten around to finding a compatible implementation of the hash yet.
@prologic@twtxt.net @anth Sounds like a good idea. The hash to conv/search url should stay local to a pod.
@prologic@twtxt.net @anth Sounds like a good idea. The hash to conv/search url should stay local to a pod.
@movq@www.uninformativ.de No argument that threading is an improvement. But I think (#hash) does that, and I think figuring out how to search should mostly be up to the client.
↳
In-reply-to
»
What am I missing here?! 😳
⤋ Read More
@prologic@twtxt.net i think i finally suss’d out my hash issue.. now to figure out why im losing avatars on restart.
↳
In-reply-to
»
What am I missing here?! 😳
⤋ Read More
@prologic@twtxt.net i think i finally suss’d out my hash issue.. now to figure out why im losing avatars on restart.
Okay, a bit better: it now preserves the author, although it prints a hash right now. Tomorrow’s problem.
↳
In-reply-to
»
I just built a poc search engine / crawler for Twtxt. I managed to crawl this pod (twtxt.net) and a couple of others (sorry @etux and @xuu I used your pods in the tests too!). So far so good. I might keep going with this and see what happens 😀
⤋ Read More
@prologic@twtxt.net yeah it reads a seed file. I’m using mine. it scans for any mention links and then scans them recursively. it reads from http/s or gopher. i don’t have much of a db yet.. it just writes to disk the feed and checks modified dates.. but I will add a db that has hashs/mentions/subjects and such.